Kotlin安卓开发-Jetpack

Kotlin安卓开发-Jetpack
Rookie_l长久以来,Android官方并没有制定一个项目架构的规范,只要能够实现功能,代码怎么编写都是你的自由。但是不同的人技术水平不同,最终编写出来的代码质量是千差万别的。
由于Android官方没有制定规范,为了追求更高的代码质量,慢慢就有第三方的社区和开发者将一些更加高级的项目架构引入到了Android平台上,如MVP、MVVM等。使用这些架构开发出来的应用程序,在代码质量、可读性、易维护性等方面都有着更加出色的表现,于是这些架构渐渐成为了主流。
后来Google或许意识到了这个情况,终于在2017年,推出了一个官方的架构组件库——Architecture Components,旨在帮助开发者编写出更加符合高质量代码规范、更具有架构设计的应用程序。2018年,Google又推出了一个全新的开发组件工具集Jetpack,并将Architecture Components作为Jetpack的一部分纳入其中。当然,Jetpack并没有就此定版,2019年又有许多新的组件被加入Jetpack当中,未来的Jetpack还会不断地继续扩充。
一、Jetpack简介
Jetpack是一个开发组件工具集,它的主要目的是帮助我们编写出更加简洁的代码,并简化我们
的开发过程。Jetpack中的组件有一个特点,它们大部分不依赖于任何Android系统版本,这意
味着这些组件通常是定义在AndroidX库当中的,并且拥有非常好的向下兼容性。
我们先来看一张Jetpack的全家桶
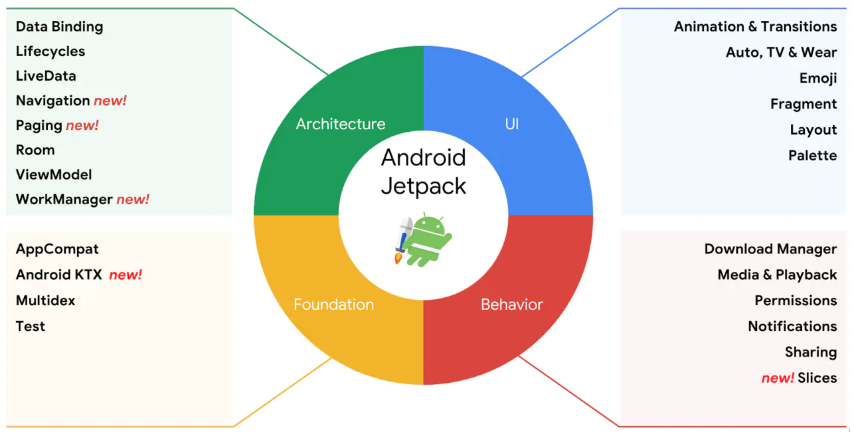
Jetpack的家族还是非常庞大的,主要由基础、架构、行为和界面这4个部分组成。你会发现,里面有许多东西是我们已经学过的,像通知、权限、Fragment都属于Jetpack。由此可见,Jetpack并不全是些新东西,只要是能够帮助开发者更好更方便地构建应用程序的组件,Google都将其纳入了Jetpack。
显然这里我们不可能将Jetpack中的每一个组件都进行学习,那将会是一个极大的工程。事实上,在这么多的组件当中,最需要我们关注的其实还是架构组件。目前Android官方最为推荐的项目架构就是MVVM,因而Jetpack中的许多架构组件是专门为MVVM架构量身打造的。
二、ViewModel
ViewModel应该可以算是Jetpack中最重要的组件之一了。其实Android平台上之所以会出现诸如MVP、MVVM之类的项目架构,就是因为在传统的开发模式下,Activity的任务实在是太重了,既要负责逻辑处理,又要控制UI展示,甚至还得处理网络回调,等等。在一个小型项目中这样写或许没有什么问题,但是如果在大型项目中仍然使用这种写法的话,那么这个项目将会变得非常臃肿并且难以维护,因为没有任何架构上的划分。
而ViewModel的一个重要作用就是可以帮助Activity分担一部分工作,它是专门用于存放与界面相关的数据的。也就是说,只要是界面上能看得到的数据,它的相关变量都应该存放在ViewModel中,而不是Activity中,这样可以在一定程度上减少Activity中的逻辑。
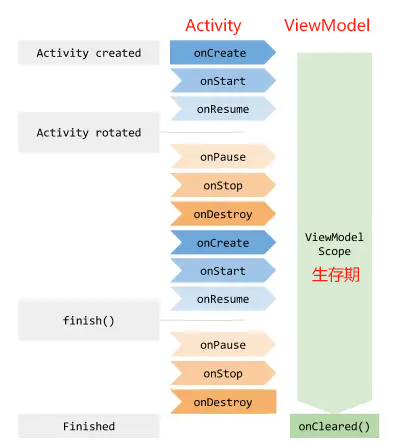
另外,ViewModel还有一个非常重要的特性。我们都知道,当手机发生横竖屏旋转的时候,Activity会被重新创建,同时存放在Activity中的数据也会丢失。而ViewModel的生命周期和Activity不同,它可以保证在手机屏幕发生旋转的时候不会被重新创建,只有当Activity退出的时候才会跟着Activity一起销毁。因此,将与界面相关的变量存放在ViewModel当中,这样即使旋转手机屏幕,界面上显示的数据也不会丢失。ViewModel的生命周期如图所示。
2.1 ViewModel的基本用法
由于Jetpack中的组件通常是以AndroidX库的形式发布的,因此一些常用的Jetpack组件会在创建Android项目时自动被包含进去。不过如果我们想要使用ViewModel组件,还需要在app/build.gradle文件中添加如下依赖:
1 | dependencies { |
通常来讲,比较好的编程规范是给每一个Activity和Fragment都创建一个对应的ViewModel,因此这里我们就为MainActivity创建一个对应的MainViewModel类,并让它继承自ViewModel,我们要实现一个计数器的功能,就可以在ViewModel中加入一个counter变量用于计数。代码如下所示:
1 | /* |
现在我们需要在界面上添加一个按钮,每点击一次按钮就让计数器加1,并且把最新的计数显示在界面上。修改activity_main.xml中的代码,如下所示:
1 |
|
接着我们开始实现计数器的逻辑,修改MainActivity中的代码,如下所示:
1 | package work.icu007.jetpacktest |
这里最需要注意的是,我们绝对不可以直接去创建ViewModel的实例,而是一定要通过ViewModelProvider来获取ViewModel的实例,具体语法规则如下:
1 | ViewModelProvider(<你的Activity或Fragment实例>).get(<你的ViewModel>::class.java) |
在 Kotlin 中,我们可以使用 get 方法的索引运算符形式 [] 来获取 ViewModel。这是因为在 ViewModelProvider 类中,get 方法被定义为一个操作符函数。在 Kotlin 中,你可以为任何函数定义一个操作符,这样就可以使用相应的符号来调用这个函数。
具体来说,ViewModelProvider 类中的 get 方法的定义大概是这样的:
1 | operator fun <T : ViewModel> get(modelClass: Class<T>): T { |
在这个定义中,operator 关键字表示这个函数可以作为一个操作符使用。因此,你可以使用 [] 来调用这个函数,就像这样:viewModel = ViewModelProvider(this)[MainViewModel::class.java]。
之所以要这么写,是因为ViewModel有其独立的生命周期,并且其生命周期要长于Activity。如果我们在onCreate()方法中创建ViewModel的实例,那么每次onCreate()方法执行的时候,ViewModel都会创建一个新的实例,这样当手机屏幕发生旋转的时候,就无法保留其中的数据了。
除此之外的其他代码应该都是非常好理解的,我们提供了一个refreshCounter()方法用来显示当前的计数,然后每次点击按钮的时候对计数器加1,并调用refreshCounter()方法刷新计数。
虽然这个例子非常简单,但这就是ViewModel的基本用法
2.2 向ViewModel传递参数
上一小节中创建的MainViewModel的构造函数中没有任何参数,但是思考一下,如果我们确实需要通过构造函数来传递一些参数,应该怎么办呢?由于所有ViewModel的实例都是通过ViewModelProvider来获取的,因此我们没有任何地方可以向ViewModel的构造函数中传递参数。
当然,这个问题也不难解决,只需要借助ViewModelProvider.Factory就可以实现了。下面我们还是通过具体的示例来学习一下。
现在的计数器虽然在屏幕旋转的时候不会丢失数据,但是如果退出程序之后再重新打开,那么之前的计数就会被清零了。接下来我们就对这一功能进行升级,保证即使在退出程序后又重新打开的情况下,数据仍然不会丢失。
相信你已经猜到了,实现这个功能需要在退出程序的时候对当前的计数进行保存,然后在重新打开程序的时候读取之前保存的计数,并传递给MainViewModel。因此,这里修改MainViewModel中的代码,如下所示:
1 | package work.icu007.jetpacktest |
现在我们给MainViewModel的构造函数添加了一个countReserved参数,这个参数用于记录之前保存的计数值,并在初始化的时候赋值给counter变量。
接下来的问题就是如何向MainViewModel的构造函数传递数据了,前面已经说了需要借助ViewModelProvider.Factory,下面我们就来看看具体应该如何实现。新建一个MainViewModelFactory类,并让它实现ViewModelProvider.Factory接口,代码如下所示:
1 | package work.icu007.jetpacktest |
可以看到,MainViewModelFactory的构造函数中也接收了一个countReserved参数。另外ViewModelProvider.Factory接口要求我们必须实现create()方法,因此这里在create()方法中我们创建了MainViewModel的实例,并将countReserved参数传了进去。为什么这里就可以创建MainViewModel的实例了呢?因为create()方法的执行时机和Activity的生命周期无关,所以不会产生之前提到的问题。
另外,我们还得在界面上添加一个清零按钮,方便用户手动将计数器清零。修改activity_main.xml中的代码,如下所示:
1 |
|
修改 MainActivity中代码,如下所示:
1 | package work.icu007.jetpacktest |
在onCreate()方法中,我们首先获取了SharedPreferences的实例,然后读取之前保存的计数值,如果没有读到的话,就使用0作为默认值。接下来在ViewModelProvider中,额外传入了一个MainViewModelFactory参数,这里将读取到的计数值传给了MainViewModelFactory的构造函数。注意,这一步是非常重要的,只有用这种写法才能将计数值最终传递给MainViewModel的构造函数。
剩下的代码就比较简单了,我们在“Clear”按钮的点击事件中对计数器进行清零,并且在onPause()方法中对当前的计数进行保存,这样可以保证不管程序是退出还是进入后台,计数都不会丢失。
2.3 Lifecycles
在编写Android应用程序的时候,可能会经常遇到需要感知Activity生命周期的情况。比如说,某个界面中发起了一条网络请求,但是当请求得到响应的时候,界面或许已经关闭了,这个时候就不应该继续对响应的结果进行处理。因此,我们需要能够时刻感知到Activity的生命周期,以便在适当的时候进行相应的逻辑控制。
感知Activity的生命周期并不复杂,早在第3章的时候我们就学习过Activity完整的生命周期流程。但问题在于,在一个Activity中去感知它的生命周期非常简单,而如果要在一个非Activity的类中去感知Activity的生命周期,应该怎么办呢?
这种需求是广泛存在的,同时也衍生出了一系列的解决方案,比如通过在Activity中嵌入一个隐藏的Fragment来进行感知,或者通过手写监听器的方式来进行感知,等等。
下面的代码演示了如何通过手写监听器的方式来对Activity的生命周期进行感知:
1 | class MyObserver { |
可以看到,这里我们为了让MyObserver能够感知到Activity的生命周期,需要专门在MainActivity中重写相应的生命周期方法,然后再通知给MyObserver。这种实现方式虽然是可以正常工作的,但是不够优雅,需要在Activity中编写太多额外的逻辑。
而Lifecycles组件就是为了解决这个问题而出现的,它可以让任何一个类都能轻松感知到Activity的生命周期,同时又不需要在Activity中编写大量的逻辑处理。
下面我们就通过具体的例子来学习Lifecycles组件的用法。新建一个MyObserver类,并让它实现DefaultLifecycleObserver接口,代码如下所示:
1 | package work.icu007.jetpacktest |
DefaultLifecycleObserver 是一个接口,它定义了一组与生命周期事件对应的方法,我们可以在自己的类中重写这些方法来响应特定的生命周期事件。
但是代码写到这里还是无法正常工作的,因为当Activity的生命周期发生变化的时候并没有人去通知MyObserver,而我们又不想像刚才一样在Activity中去一个个手动通知。这个时候就得借助LifecycleOwner这个好帮手了,它可以使用如下的语法结构让MyObserver得到通知:
1 | lifecycleOwner.lifecycle.addObserver(MyObserver()) |
首先调用LifecycleOwner的getLifecycle()方法,得到一个Lifecycle对象,然后调用它的addObserver()方法来观察LifecycleOwner的生命周期,再把MyObserver的实例传进去就可以了。
那么接下来的问题就是,LifecycleOwner又是什么呢?怎样才能获取一个LifecycleOwner的实例?
当然,我们可以自己去实现一个LifecycleOwner,但通常情况下这是完全没有必要的。因为只要你的Activity是继承自AppCompatActivity的,或者你的Fragment是继承自androidx.fragment.app.Fragment的,那么它们本身就是一个LifecycleOwner的实例,这部分工作已经由AndroidX库自动帮我们完成了。也就是说,在MainActivity当中就可以这样写:
1 | package work.icu007.jetpacktest |
没错只需要添加:
1 | val myObserver = MyObserver() |
这样两行代码,MyObserver就能自动感知到Activity的生命周期了
这些就是Lifecycles组件最常见的用法了。不过目前MyObserver虽然能够感知到Activity的生命周期发生了变化,却没有办法主动获知当前的生命周期状态。要解决这个问题也不难,只需要在MyObserver的构造函数中将Lifecycle对象传进来即可,如下所示:
1 | class MyObserver(val lifecycle: Lifecycle) : DefaultLifecycleObserver { |
有了Lifecycle对象之后,我们就可以在任何地方调用lifecycle.currentState来主动获知当前的生命周期状态。lifecycle.currentState返回的生命周期状态是一个枚举类型,一共有INITIALIZED、DESTROYED、CREATED、STARTED、RESUMED这5种状态类型,它们与Activity的生命周期回调所对应的关系如图:
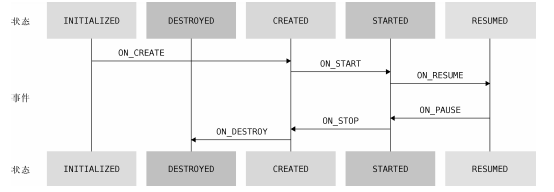
也就是说,当获取的生命周期状态是CREATED的时候,说明onCreate()方法已经执行了,但是onStart()方法还没有执行。当获取的生命周期状态是STARTED的时候,说明onStart()方法已经执行了,但是onResume()方法还没有执行,以此类推。
2.4 LiveData
LiveData是Jetpack提供的一种响应式编程组件,它可以包含任何类型的数据,并在数据发生变化的时候通知给观察者。LiveData特别适合与ViewModel结合在一起使用,虽然它也可以单独用在别的地方,但是在绝大多数情况下,它是使用在ViewModel当中的。
2.4.1 LiveData的基本用法
之前我们编写的那个计数器虽然功能非常简单,但其实是存在问题的。目前的逻辑是,当每次点击“Plus One”按钮时,都会先给ViewModel中的计数加1,然后立即获取最新的计数。这种方式在单线程模式下确实可以正常工作,但如果ViewModel的内部开启了线程去执行一些耗时逻辑,那么在点击按钮后就立即去获取最新的数据,得到的肯定还是之前的数据。
我们一直使用的都是在Activity中手动获取ViewModel中的数据这种交互方式,但是ViewModel却无法将数据的变化主动通知给Activity。
那么把Activity的实例传给ViewModel,这样ViewModel就能主动对Activity进行通知了,这样做可行吗?注意,千万不可以这么做。不要忘了,ViewModel的生命周期是长于Activity的,如果把Activity的实例传给ViewModel,就很有可能会因为Activity无法释放而造成内存泄漏,这是一种非常错误的做法。
而这个问题的解决方案也是显而易见的,就是使用我们本节即将学习的LiveData。正如前面所描述的一样,LiveData可以包含任何类型的数据,并在数据发生变化的时候通知给观察者。也就是说,如果我们将计数器的计数使用LiveData来包装,然后在Activity中去观察它,就可以主动将数据变化通知给Activity了。
介绍完了工作原理,接下来我们开始编写具体的代码,修改MainViewModel中的代码,如下所示:
1 | class MainViewModel(countReserved: Int) : ViewModel() { |
这里我们将counter变量修改成了一个MutableLiveData对象,并指定它的泛型为Int,表示它包含的是整型数据。MutableLiveData是一种可变的LiveData,它的用法很简单,主要有3种读写数据的方法,分别是getValue()、setValue()和postValue()方法。getValue()方法用于获取LiveData中包含的数据;setValue()方法用于给LiveData设置数据,但是只能在主线程中调用;postValue()方法用于在非主线程中给LiveData设置数据。而上述代码其实就是调用getValue()和setValue()方法对应的语法糖写法。
可以看到,这里在init结构体中给counter设置数据,这样之前保存的计数值就可以在初始化的时候得到恢复。接下来我们新增了plusOne()和clear()这两个方法,分别用于给计数加1以及将计数清零。plusOne()方法中的逻辑是先获取counter中包含的数据,然后给它加1,再重新设置到counter当中。注意调用LiveData的getValue()方法所获得的数据是可能为空的,因此这里使用了一个?:操作符,当获取到的数据为空时,就用0来作为默认计数。
这样我们就借助LiveData将MainViewModel的写法改造完了,接下来开始改造MainActivity,代码如下所示:
1 | class MainActivity : AppCompatActivity() { |
很显然,在“Plus One”按钮的点击事件中我们应该去调用MainViewModel的plusOne()方法,而在“Clear”按钮的点击事件中应该去调用MainViewModel的clear()方法。另外,在onPause()方法中,我们将获取当前计数的写法改造了一下,这部分内容还是很好理解的。
接下来到最关键的地方了,这里调用了viewModel.counter的observe()方法来观察数据的变化。经过对MainViewModel的改造,现在counter变量已经变成了一个LiveData对象,任何LiveData对象都可以调用它的observe()方法来观察数据的变化。observe()方法接收两个参数:第一个参数是一个LifecycleOwner对象,有没有觉得很熟悉?没错,Activity本身就是一个LifecycleOwner对象,因此直接传this就好;第二个参数是一个Observer接口,当counter中包含的数据发生变化时,就会回调到这里,因此我们在这里将最新的计数更新到界面上即可。
1 | viewModel.counter.observe(this, Observer { count -> |
这里使用了高阶函数和 lambda 表达式。在 Kotlin 中,如果一个函数的最后一个参数是函数,那么你可以将一个 lambda 表达式传递给这个函数。并且,如果这个 lambda 表达式是这个函数调用的唯一参数,那么你可以在函数名和 lambda 表达式之间省略括号。
如果一个接口只有一个未实现的方法(我们称之为函数式接口),那么可以使用 lambda 表达式来代替这个接口的匿名类实例。
在上述代码中,Observer 是一个函数式接口,它只有一个未实现的方法:onChanged。因此,我们可以使用一个 lambda 表达式 count -> { ... } 来代替 Observer 的匿名类实例。在这个 lambda 表达式中,count 是 onChanged 方法的参数,{ ... } 是 onChanged 方法的主体。
所以,当 observe 方法需要一个 Observer 参数时,我们可以直接传入一个 lambda 表达式。当被观察的数据发生变化时,这个 lambda 表达式就会被调用,就像 onChanged 方法被调用一样。
现在我们的代码更科学,也更合理,而且不用担心ViewModel的内部会不会开启线程执行耗时逻辑。不过需要注意的是,如果你需要在子线程中给LiveData设置数据,一定要调用postValue()方法,而不能再使用setValue()方法,否则会发生崩溃。
另外,关于LiveData的observe()方法,我还想再多说几句,因为我当初在学习这部分内容时也产生过疑惑。observe()方法是一个Java方法,如果你观察一下Observer接口,会发现这是一个单抽象方法接口,只有一个待实现的onChanged()方法。既然是单抽象方法接口,为什么在调用observe()方法时却没有使用我们之前学习的Java函数式API的写法呢?
这是一种非常特殊的情况,因为observe()方法接收的另一个参数LifecycleOwner也是一个单抽象方法接口。当一个Java方法同时接收两个单抽象方法接口参数时,要么同时使用函数式API的写法,要么都不使用函数式API的写法。由于我们第一个参数传的是this,因此第二个参数就无法使用函数式API的写法了。
不过在2019年的Google I/O大会上,Android团队官宣了Kotlin First,并且承诺未来会在Jetpack中提供更多专门面向Kotlin语言的API。其中,lifecycle-livedata-ktx就是一个专门为Kotlin语言设计的库,这个库在2.2.0版本中加入了对observe()方法的语法扩展。我们只需要在app/build.gradle文件中添加如下依赖:
1 | dependencies { |
然后就可以使用如下语法结构的observe()方法了:
1 | viewModel.counter.observe(this) { count -> |
以上就是LiveData的基本用法。虽说现在的写法可以正常工作,但其实这仍然不是最规范的LiveData用法,主要的问题就在于我们将counter这个可变的LiveData暴露给了外部。这样即使是在ViewModel的外面也是可以给counter设置数据的,从而破坏了ViewModel数据的封装性,同时也可能带来一定的风险。
比较推荐的做法是,永远只暴露不可变的LiveData给外部。这样在非ViewModel中就只能观察LiveData的数据变化,而不能给LiveData设置数据。下面我们就看一下如何改造MainViewModel来实现这样的功能:
1 | class MainViewModel(countReserved: Int) : ViewModel() { |
在 Kotlin 中,我们可以在属性声明的同时定义自定义的 getter 方法。这就是为什么 get() = _counter 可以直接跟在 val counter: LiveData<Int> 声明后面。
当你这样声明一个属性时:
1 | val counter: LiveData<Int> |
我们实际上做了两件事情:
- 声明了一个名为
counter的只读属性,它的类型是LiveData<Int>。 - 为
counter属性定义了一个自定义的 getter 方法,这个方法返回_counter的值。
所以,每次访问 counter 属性时,实际上调用的是这个自定义的 getter 方法,返回的是 _counter 的值。
这种语法是 Kotlin 中属性声明的一部分,它使得我们可以在声明属性的同时定义自定义的 getter 或 setter 方法。
可以看到,这里先将原来的counter变量改名为_counter变量,并给它加上private修饰符,这样_counter变量对于外部就是不可见的了。然后我们又新定义了一个counter变量,将它的类型声明为不可变的LiveData,并在它的get()属性方法中返_counter变量。这样,当外部调用counter变量时,实际上获得的就是_counter的实例,但是无法给counter设置数据,从而保证了ViewModel的数据封装性。
目前这种写法可以说是非常规范了,这也是Android官方最为推荐的写法.
2.4.2 map和switchMap
LiveData的基本用法虽说可以满足大部分的开发需求,但是当项目变得复杂之后,可能会出现一些更加特殊的需求。LiveData为了能够应对各种不同的需求场景,提供了两种转换方法:map()和switchMap()方法。下面我们就学习这两种转换方法的具体用法和使用场景。
先来看map()方法,这个方法的作用是将实际包含数据的LiveData和仅用于观察数据的LiveData进行转换。那么什么情况下会用到这个方法呢?下面我来举一个例子。
比如说有一个User类,User中包含用户的姓名和年龄,定义如下:
1 | data class User(var firstName: String, var lastName: String, var age: Int) |
我们可以在ViewModel中创建一个相应的LiveData来包含User类型的数据,如下所示:
1 | class MainViewModel(countReserved: Int) : ViewModel() { |
到目前为止,这和我们在上一小节中学习的内容并没有什么区别。可是如果MainActivity中明确只会显示用户的姓名,而完全不关心用户的年龄,那么这个时候还将整个User类型的LiveData暴露给外部,就显得不那么合适了。
而map()方法就是专门用于解决这种问题的,它可以将User类型的LiveData自由地转型成任意其他类型的LiveData,下面我们来看一下具体的用法:
1 | class MainViewModel(countReserved: Int) : ViewModel() { |
这段代码中,userName 是一个 LiveData<String> 类型的属性,它的值是由 userLiveData 映射(map)得到的。
userLiveData 是一个 MutableLiveData<User> 类型的属性,它的值可以改变,而且每次值改变时,所有观察 userLiveData 的观察者都会收到通知。
map 是一个扩展函数,它接受一个 lambda 表达式作为参数,这个 lambda 表达式定义了如何将 userLiveData 的值转换为 userName 的值。在这个例子中,lambda 表达式是 { user -> "${user.firstName} ${user.lastName}" },它将 User 对象转换为一个字符串,这个字符串是 User 对象的 firstName 和 lastName 属性的拼接。
所以,每次 userLiveData 的值改变时,userName 的值也会相应地改变。例如,如果 userLiveData 的值改变为 User("John", "Doe", 30),那么 userName 的值就会改变为 "John Doe"。
可以看到,这里我们调用了MutableLiveData的map()方法来对LiveData的数据类型进行转换。map()方法接收一个参数,这个参数是一个转换函数,我们在转换函数里编写具体的转换逻辑即可。这里的逻辑也很简单,就是将User对象转换成一个只包含用户姓名的字符串。
另外,我们还将userLiveData声明成了private,以保证数据的封装性。外部使用的时候只要观察userName这个LiveData就可以了。当userLiveData的数据发生变化时,map()方法会监听到变化并执行转换函数中的逻辑,然后再将转换之后的数据通知给userName的观察者。
这就是map()方法的用法和使用场景,非常好理解。
接下来,我们开始学习switchMap()方法,虽然它的使用场景非常固定,但是可能比map()方法要更加常用。
前面我们所学的所有内容都有一个前提:LiveData对象的实例都是在ViewModel中创建的。然而在实际的项目中,不可能一直是这种理想情况,很有可能ViewModel中的某个LiveData对象是调用另外的方法获取的。
下面就来模拟一下这种情况,新建一个Repository单例类,代码如下所示:
1 | object Repository { |
这里我们在Repository类中添加了一个getUser()方法,这个方法接收一个userId参数。按照正常的编程逻辑,我们应该根据传入的userId参数去服务器请求或者到数据库中查找相应的User对象,但是这里只是模拟示例,因此每次将传入的userId当作用户姓名来创建一个新的User对象即可。
需要注意的是,getUser()方法返回的是一个包含User数据的LiveData对象,而且每次调用getUser()方法都会返回一个新的LiveData实例。
然后我们在MainViewModel中也定义一个getUser()方法,并且让它调用Repository的getUser()方法来获取LiveData对象:
1 | class MainViewModel(countReserved: Int) : ViewModel() { |
接下来的问题就是,在Activity中如何观察LiveData的数据变化呢?既然getUser()方法返回的就是一个LiveData对象,那么我们可不可以直接在Activity中使用如下写法呢?
1 | viewModel.getUser(userId).observe(this) { user -> |
请注意,这么做是完全错误的。因为每次调用getUser()方法返回的都是一个新的LiveData实例,而上述写法会一直观察老的LiveData实例,从而根本无法观察到数据的变化。你会发现,这种情况下的LiveData是不可观察的。
这个时候,switchMap()方法就可以派上用场了。正如前面所说,它的使用场景非常固定:如果ViewModel中的某个LiveData对象是调用另外的方法获取的,那么我们就可以借助switchMap()方法,将这个LiveData对象转换成另外一个可观察的LiveData对象。
修改MainViewModel中的代码,如下所示:
1 | package work.icu007.jetpacktest |
这里我们定义了一个新的userIdLiveData对象,用来观察userId的数据变化,然后调用了MutableLiveData的switchMap()方法,用来对另一个可观察的LiveData对象进行转换。
switchMap()方法同样接收一个参数:这个参数是一个转换函数,注意,我们必须在这个转换函数中返回一个LiveData对象,因为switchMap()方法的工作原理就是要将转换函数中返回的LiveData对象转换成另一个可观察的LiveData对象。那么很显然,我们只需要在转换函数中调用Repository的getUser()方法来得到LiveData对象,并将它返回就可以了。
为了能更清晰地理解switchMap()的用法,我们再来梳理一遍它的整体工作流程。首先,当外部调用MainViewModel的getUser()方法来获取用户数据时,并不会发起任何请求或者函数调用,只会将传入的userId值设置到userIdLiveData当中。一旦userIdLiveData的数据发生变化,那么观察userIdLiveData的switchMap()方法就会执行,并且调用我们编写的转换函数。然后在转换函数中调用Repository.getUser()方法获取真正的用户数据。同时,switchMap()方法会将Repository.getUser()方法返回的LiveData对象转换成一个可观察的LiveData对象,对于Activity而言,只要去观察这个LiveData对象就可以了。
下面我们就来测试一下,修改activity_main.xml文件,在里面新增一个“Get User”按钮:
1 |
|
然后修改MainActivity中的代码,如下所示:
1 | class MainActivity : AppCompatActivity() { |
具体的用法就是这样了,我们在“Get User”按钮的点击事件中使用随机函数生成了一个userId,然后调用MainViewModel的getUser()方法来获取用户数据,但是这个方法现在不会有任何返回值了。等数据获取完成之后,可观察LiveData对象的observe()方法将会得到通知,我们在这里将获取的用户名显示到界面上。
。在刚才的例子当中,我们调
用MainViewModel的getUser()方法时传入了一个userId参数,为了能够观察这个参数的数据变化,又构建了一个userIdLiveData,然后在switchMap()方法中再去观察这个LiveData对象就可以了。但是ViewModel中某个获取数据的方法有可能是没有参数的,这个时候代码应该怎么写呢?
其实这个问题并没有想象中复杂,写法基本上和原来是相同的,只是在没有可观察数据的情况下,我们需要创建一个空的LiveData对象,示例写法如下:
1 | class MyViewModel : ViewModel() { |
可以看到,这里我们定义了一个不带参数的refresh()方法,又对应地定义了一个refreshLiveData,但是它不需要指定具体包含的数据类型,因此这里我们将LiveData的泛型指定成Any?即可。
接下来就是点睛之笔的地方了,在refresh()方法中,我们只是将refreshLiveData原有的数据取出来(默认是空),再重新设置到refreshLiveData当中,这样就能触发一次数据变化。是的,LiveData内部不会判断即将设置的数据和原有数据是否相同,只要调用了setValue()或postValue()方法,就一定会触发数据变化事件。
然后我们在Activity中观察refreshResult这个LiveData对象即可,这样只要调用了refresh()方法,观察者的回调函数中就能够得到最新的数据。
学到现在,只看到了LiveData与ViewModel结合在一起使用,好像和上一节的Lifecycles组件没什么关系嘛。
其实并不是这样的,LiveData之所以能够成为Activity与ViewModel之间通信的桥梁,并且还不会有内存泄漏的风险,靠的就是Lifecycles组件。LiveData在内部使用了Lifecycles组件来自我感知生命周期的变化,从而可以在Activity销毁的时候及时释放引用,避免产生内存泄漏的问题。
另外,由于要减少性能消耗,当Activity处于不可见状态的时候(比如手机息屏,或者被其他的Activity遮挡),如果LiveData中的数据发生了变化,是不会通知给观察者的。只有当Activity重新恢复可见状态时,才会将数据通知给观察者,而LiveData之所以能够实现这种细节的优化,依靠的还是Lifecycles组件。
还有一个小细节,如果在Activity处于不可见状态的时候,LiveData发生了多次数据变化,当Activity恢复可见状态时,只有最新的那份数据才会通知给观察者,前面的数据在这种情况下相当于已经过期了,会被直接丢弃。
2.5 Room
之前学习了SQLite数据库的使用方法,不过当时仅仅是使用了一些原生的API来进行数据的增删改查操作。这些原生API虽然简单易用,但是如果放到大型项目当中的话,会非常容易让项目的代码变得混乱,除非你进行了很好的封装。为此市面上出现了诸多专门为Android数据库设计的ORM框架。
ORM(Object Relational Mapping)也叫对象关系映射。简单来讲,我们使用的编程语言是面向对象语言,而使用的数据库则是关系型数据库,将面向对象的语言和面向关系的数据库之间建立一种映射关系,这就是ORM了。
那么使用ORM框架有什么好处呢?它赋予了我们一个强大的功能,就是可以用面向对象的思维来和数据库进行交互,绝大多数情况下不用再和SQL语句打交道了,同时也不用担心操作数据库的逻辑会让项目的整体代码变得混乱。
由于许多大型项目中会用到数据库的功能,为了帮助我们编写出更好的代码,Android官方推出了一个ORM框架,并将它加入了Jetpack当中,就是Room。
2.5.1 使用Room进行增删改查
先来看一下Room的整体结构。它主要由Entity、Dao和Database这3部分组成,每个部分都有明确的职责,详细说明如下。
- Entity:用于定义封装实际数据的实体类,每个实体类都会在数据库中有一张对应的表,并且表中的列是根据实体类中的字段自动生成的。
- Dao:Dao是数据访问对象的意思,通常会在这里对数据库的各项操作进行封装,在实际编程的时候,逻辑层就不需要和底层数据库打交道了,直接和Dao层进行交互即可。
- Database:用于定义数据库中的关键信息,包括数据库的版本号、包含哪些实体类以及提供Dao层的访问实例。
首先要使用Room,需要在app/build.gradle文件中添加如下的依赖:
1 | plugins { |
这里新增了一个kotlin-kapt插件,同时在dependencies闭包中添加了两个Room的依赖库。由于Room会根据我们在项目中声明的注解来动态生成代码,因此这里一定要使用kapt引入Room的编译时注解库,而启用编译时注解功能则一定要先添加kotlin-kapt插件。注意,**kapt只能在Kotlin项目中使用,如果是Java项目的话,使用annotationProcessor即可。**下面我们就按照刚才介绍的Room的3个组成部分一一来进行实现,首先是定义Entity,也就是实体类。
好消息是JetpackTest项目中已经存在一个实体类了,就是我们在学习LiveData时创建的User类。然而User类目前只包含firstName、lastName和age这3个字段,但是一个良好的数据库编程建议是,给每个实体类都添加一个id字段,并将这个字段设为主键。于是我们对User类进行如下改造,并完成实体类的声明:
1 |
|
可以看到,这里我们在User的类名上使用@Entity注解,将它声明成了一个实体类,然后在User类中添加了一个id字段,并使用@PrimaryKey注解将它设为了主键,再把autoGenerate参数指定成true,使得主键的值是自动生成的。
这样实体类部分就定义好了,不过这里简单起见,只定义了一个实体类,在实际项目当中,你可能需要根据具体的业务逻辑定义很多个实体类。当然,每个实体类定义的方式都是差不多的,最多添加一些实体类之间的关联。接下来开始定义Dao,这部分也是Room用法中最关键的地方,因为所有访问数据库的操作都是在这里封装的。
访问数据库的操作无非就是增删改查这4种,但是业务需求却是千变万化的。而Dao要做的事情就是覆盖所有的业务需求,使得业务方永远只需要与Dao层进行交互,而不必和底层的数据库打交道。
那么下面我们就来看一下一个Dao具体是如何实现的。新建一个UserDao接口,注意必须使用接口,这点和Retrofit是类似的,然后在接口中编写如下代码:
1 | package work.icu007.jetpacktest |
UserDao接口的上面使用了一个@Dao注解,这样Room才能将它识别成一个Dao。UserDao的内部就是根据业务需求对各种数据库操作进行的封装。数据库操作通常有增删改查这4种,因此Room也提供了@Insert、@Delete、@Update和@Query这4种相应的注解。
可以看到,**insertUser()方法上面使用了@Insert注解,表示会将参数中传入的User对象插入数据库中,插入完成后还会将自动生成的主键id值返回。updateUser()方法上面使用了@Update注解,表示会将参数中传入的User对象更新到数据库当中。deleteUser()方法上面使用了@Delete注解,表示会将参数传入的User对象从数据库中删除。**以上几种数据库操作都是直接使用注解标识即可,不用编写SQL语句。
但是如果想要从数据库中查询数据,或者使用非实体类参数来增删改数据,那么就必须编写SQL语句了。比如说我们在UserDao接口中定义了一个loadAllUsers()方法,用于从数据库中查询所有的用户,如果只使用一个@Query注解,Room将无法知道我们想要查询哪些数据,因此必须在@Query注解中编写具体的SQL语句才行。我们还可以将方法中传入的参数指定到SQL语句当中,比如loadUsersOlderThan()方法就可以查询所有年龄大于指定参数的用户。另外,如果是使用非实体类参数来增删改数据,那么也要编写SQL语句才行,而且这个时候不能使用@Insert、@Delete或@Update注解,而是都要使用@Query注解才行,参考deleteUserByLastName()方法的写法。
这样我们就大体定义了添加用户、修改用户数据、查询用户、删除用户这几种数据库操作接口,在实际项目中你根据真实的业务需求来进行定义即可。
虽然使用Room需要经常编写SQL语句这一点不太友好,但是SQL语句确实可以实现更加多样化的逻辑,而且Room是支持在编译时动态检查SQL语句语法的。也就是说,如果我们编写的SQL语句有语法错误,编译的时候就会直接报错,而不会将错误隐藏到运行的时候才发现,也算是大大减少了很多安全隐患吧。
接下来我们进入最后一个环节:定义Database。这部分内容的写法是非常固定的,只需要定义好3个部分的内容:数据库的版本号、包含哪些实体类,以及提供Dao层的访问实例。新建一个AppDatabase.kt文件,代码如下所示:
1 | package work.icu007.jetpacktest |
可以看到,这里我们在AppDatabase类的头部使用了@Database注解,并在注解中声明了数据库的版本号以及包含哪些实体类,多个实体类之间用逗号隔开即可。另外,AppDatabase类必须继承自RoomDatabase类,并且一定要使用abstract关键字将它声明成抽象类,然后提供相应的抽象方法,用于获取之前编写的Dao的实例,比如这里提供的userDao()方法。不过我们只需要进行方法声明就可以了,具体的方法实现是由Room在底层自动完成的。
紧接着,我们在companion object结构体中编写了一个单例模式,因为原则上全局应该只存在一份AppDatabase的实例。这里使用了instance变量来缓存AppDatabase的实例,然后在getDatabase()方法中判断:如果instance变量不为空就直接返回,否则就调用Room.databaseBuilder()方法来构建一个AppDatabase的实例。databaseBuilder()方法接收3个参数,注意第一个参数一定要使用applicationContext,而不能使用普通的context,否则容易出现内存泄漏的情况,关于applicationContext的详细内容我们将会在第14章中学习。第二个参数是AppDatabase的Class类型,第三个参数是数据库名,这些都比较简单。最后调用build()方法完成构建,并将创建出来的实例赋值给instance变量,然后返回当前实例即可。
这样我们就把Room所需要的一切都定义好了,接下来要做的事情就是对它进行测试。修改activity_main.xml中的代码,在里面加入用于增删改查的4个按钮:
1 |
|
然后修改MainActivity中的代码,分别在这4个按钮的点击事件中实现增删改查的逻辑,如下所示:
1 | class MainActivity : AppCompatActivity() { |
这段代码的逻辑还是很简单的。首先获取了UserDao的实例,并创建两个User对象。然后在“Add Data”按钮的点击事件中,我们调用了UserDao的insertUser()方法,将这两个User对象插入数据库中,并将insertUser()方法返回的主键id值赋值给原来的User对象。
之所以要这么做,是因为使用@Update和@Delete注解去更新和删除数据时都是基于这个id值来操作的。
然后在“Update Data”按钮的点击事件中,我们将user1的年龄修改成了42岁,并调用UserDao的updateUser()方法来更新数据库中的数据。在“Delete Data”按钮的点击事件中,我们调用了UserDao的deleteUserByLastName()方法,删除所有lastName是Hanks的用户。在“Query Data”按钮的点击事件中,我们调用了UserDao的loadAllUsers()方法,查询并打印数据库中所有的用户。
另外,由于数据库操作属于耗时操作,Room默认是不允许在主线程中进行数据库操作的,因此上述代码中我们将增删改查的功能都放到了子线程中。不过为了方便测试,Room还提供了一个更加简单的方法,如下所示:
1 | Room.databaseBuilder( |
在构建AppDatabase实例的时候,加入一个allowMainThreadQueries()方法,这样Room就允许在主线程中进行数据库操作了,这个方法建议只在测试环境下使用。
2.5.2 Room的数据库升级
数据库结构不可能在设计好了之后就永远一成不变,随着需求和版本的变更,数据库也是需要升级的。不过遗憾的是,Room在数据库升级方面设计得非常烦琐,基本上没有比使用原生的SQLiteDatabase简单到哪儿去,每一次升级都需要手动编写升级逻辑才行。
不过,如果只是在开发测试阶段,不想编写那么烦琐的数据库升级逻辑,Room倒也提供了一个简单粗暴的方法,如下所示:
1 | Room.databaseBuilder(context.applicationContext, AppDatabase::class.java, "app_database") |
在构建AppDatabase实例的时候,加入一个fallbackToDestructiveMigration()方法。这样只要数据库进行了升级,Room就会将当前的数据库销毁,然后再重新创建,随之而来的副作用就是之前数据库中的所有数据就全部丢失了。假如产品还在开发和测试阶段,这个方法是可以使用的,但是一旦产品对外发布之后,如果造成了用户数据丢失,那可是严重的事故。因此接下来我们还是老老实实学习一下在Room中升级数据库的正规写法。
随着业务逻辑的升级,现在我们打算在数据库中添加一张Book表,那么首先要做的就是创建一个Book的实体类,如下所示:
1 |
|
可以看到,Book类中包含了主键id、书名、页数这几个字段,并且我们还使用@Entity注解将它声明成了一个实体类。
然后创建一个BookDao接口,并在其中随意定义一些API:
1 |
|
接下来修改AppDatabase中的代码,在里面编写数据库升级的逻辑,如下所示:
1 |
|
首先在@Database注解中,我们将版本号升级成了2,并将Book类添加到了实体类声明中,然后又提供了一个bookDao()方法用于获取BookDao的实例。
接下来就是关键的地方了,在companion object结构体中,我们实现了一个Migration的匿名类,并传入了1和 2这两个参数,表示当数据库版本从1升级到2的时候就执行这个匿名类中的升级逻辑。匿名类实例的变量命名也比较有讲究,这里命名成MIGRATION_1_2,可读性更高。由于我们要新增一张Book表,所以需要在migrate()方法中编写相应的建表语句。另外必须注意的是,Book表的建表语句必须和Book实体类中声明的结构完全一致,否则Room就会抛出异常。
最后在构建AppDatabase实例的时候,加入一个addMigrations()方法,并把MIGRATION_1_2传入即可。
现在当我们进行任何数据库操作时,Room就会自动根据当前数据库的版本号执行这些升级逻辑,从而让数据库始终保证是最新的版本。
不过,每次数据库升级并不一定都要新增一张表,也有可能是向现有的表中添加新的列。这种情况只需要使用alter语句修改表结构就可以了,我们来看一下具体的操作过程。
现在Book的实体类中只有id、书名、页数这几个字段,而我们想要再添加一个作者字段,代码如下所示:
1 |
|
既然实体类的字段发生了变动,那么对应的数据库表也必须升级了,所以这里修改AppDatabase中的代码,如下所示:
1 |
|
2.6 WorkManager
Android的后台机制是一个很复杂的话题,在很早之前,Android系统的后台功能是非常开放的,Service的优先级也很高,仅次于Activity,那个时候可以在Service中做很多事情。但由于后台功能太过于开放,每个应用都想无限地占用后台资源,导致手机的内存越来越紧张,耗电越来越快,也变得越来越卡。为了解决这些情况,基本上Android系统每发布一个新版本,后台权限都会被进一步收紧。
从4.4系统开始AlarmManager的触发时间由原来的精准变为不精准,5.0系统中加入了JobScheduler来处理后台任务,6.0系统中引入了Doze和App Standby模式用于降低手机被后台唤醒的频率,从8.0系统开始直接禁用了Service的后台功能,只允许使用前台Service。当然,还有许许多多小细节的修改,我没能全部列举出来。
这么频繁的功能和API变更,让开发者就很难受了,到底该如何编写后台代码才能保证应用程序在不同系统版本上的兼容性呢?为了解决这个问题,Google推出了WorkManager组件。WorkManager很适合用于处理一些要求定时执行的任务,它可以根据操作系统的版本自动选择底层是使用AlarmManager实现还是JobScheduler实现,从而降低了我们的使用成本。另外,它还支持周期性任务、链式任务处理等功能,是一个非常强大的工具。
不过,我们还得先明确一件事情:**WorkManager和Service并不相同,也没有直接的联系。Service是Android系统的四大组件之一,它在没有被销毁的情况下是一直保持在后台运行的。而WorkManager只是一个处理定时任务的工具,它可以保证即使在应用退出甚至手机重启的情况下,之前注册的任务仍然将会得到执行,因此WorkManager很适合用于执行一些定期和服务器进行交互的任务,比如周期性地同步数据,等等。**
另外,使用WorkManager注册的周期性任务不能保证一定会准时执行,这并不是bug,而是系统为了减少电量消耗,可能会将触发时间临近的几个任务放在一起执行,这样可以大幅度地减少CPU被唤醒的次数,从而有效延长电池的使用时间。
那么下面我们就开始学习WorkManager的具体用法。
2.6.1 WorkManager的基本用法
要想使用WorkManager,需要先在app/build.gradle文件中添加如下的依赖:
1 | dependencies { |
WorkManager的基本用法其实非常简单,主要分为以下3步:
- 定义一个后台任务,并实现具体的任务逻辑;
- 配置该后台任务的运行条件和约束信息,并构建后台任务请求;
- 将该后台任务请求传入
WorkManager的enqueue()方法中,系统会在合适的时间运行。
第一步要定义一个后台任务,这里创建一个SimpleWorker类,代码如下所示:
1 | class SimpleWorker(context: Context, params: WorkerParameters) : Worker(context, params) { |
后台任务的写法非常固定,也很好理解。首先每一个后台任务都必须继承自Worker类,并调用它唯一的构造函数。然后重写父类中的doWork()方法,在这个方法中编写具体的后台任务逻辑即可。
doWork()方法不会运行在主线程当中,因此你可以放心地在这里执行耗时逻辑,不过这里简单起见只是打印了一行日志。另外,doWork()方法要求返回一个Result对象,用于表示任务的运行结果,成功就返回Result.success(),失败就返回Result.failure()。除此之外,还有一个Result.retry()方法,它其实也代表着失败,只是可以结合WorkRequest.Builder的setBackoffCriteria()方法来重新执行任务,我们稍后会进行学习。
没错,就是这么简单,这样一个后台任务就定义好了。接下来可以进入第二步,配置该后台任务的运行条件和约束信息。
这一步其实也是最复杂的一步,因为可配置的内容非常多,不过目前我们还只是学习WorkManager的基本用法,因此只进行最基本的配置就可以了,代码如下所示:
1 | val request = OneTimeWorkRequest.Builder(SimpleWorker::class.java).build() |
可以看到,只需要把刚才创建的后台任务所对应的Class对象传入OneTimeWorkRequest.Builder的构造函数中,然后调用build()方法即可完成构建。
OneTimeWorkRequest.Builder是WorkRequest.Builder的子类,用于构建单次运行的后台任务请求。WorkRequest.Builder还有另外一个子类PeriodicWorkRequest.Builder,可用于构建周期性运行的后台任务请求,但是为了降低设备性能消耗,PeriodicWorkRequest.Builder构造函数中传入的运行周期间隔不能短于15分钟,示例代码如下:
1 | val request = PeriodicWorkRequest.Builder(SimpleWorker::class.java, 15, TimeUnit.MINUTES).build() |
最后一步,将构建出的后台任务请求传入WorkManager的enqueue()方法中,系统就会在合适的时间去运行了:
1 | WorkManager.getInstance(context).enqueue(request) |
在activity_main.xml中新增一个“Do Work”按钮,如下所示:
1 |
|
接下来修改MainActivity中的代码,如下所示:
1 | class MainActivity : AppCompatActivity() { |
在“Do Work”按钮的点击事件中构建后台任务请求,并将请求传入WorkManager的enqueue()方法中。后台任务的具体运行时间是由我们所指定的约束以及系统自身的一些优化所决定的,由于这里没有指定任何约束,因此后台任务基本上会在点击按钮之后立刻运行。
2.6.2 使用WorkManager处理复杂的任务
在上一小节中,虽然我们成功运行了一个后台任务,但是由于不能控制它的具体运行时间,因此并没有什么太大的实际用处。当然,WorkManager是不可能没有提供这样的接口的,事实上除了运行时间之外,WorkManager还允许我们控制许多其他方面的东西,下面就来具体看一下吧。
首先从最简单的看起,让后台任务在指定的延迟时间后运行,只需要借助setInitialDelay()方法就可以了,代码如下所示:
1 | val request = OneTimeWorkRequest.Builder(SimpleWorker::class.java) |
这就表示我们希望让SimpleWorker这个后台任务在5分钟后运行。你可以自由选择时间的单位,毫秒、秒、分钟、小时、天都可以。
可以控制运行时间之后,我们再增加一些别的功能,比如说给后台任务请求添加标签:
1 | val request = OneTimeWorkRequest.Builder(SimpleWorker::class.java) |
那么添加了标签有什么好处呢?最主要的一个功能就是我们可以通过标签来取消后台任务请求:
1 | WorkManager.getInstance(this).cancelAllWorkByTag("simple") |
当然,即使没有标签,也可以通过id来取消后台任务请求:
1 | WorkManager.getInstance(this).cancelWorkById(request.id) |
但是,使用id只能取消单个后台任务请求,而使用标签的话,则可以将同一标签名的所有后台任务请求全部取消,这个功能在逻辑复杂的场景下尤其有用。
除此之外,我们也可以使用如下代码来一次性取消所有后台任务请求:
1 | WorkManager.getInstance(this).cancelAllWork() |
另外,我们在上一小节中讲到,如果后台任务的doWork()方法中返回了Result.retry(),那么是可以结合setBackoffCriteria()方法来重新执行任务的,具体代码如下所示:
1 | val request = OneTimeWorkRequest.Builder(SimpleWork::class.java) |
setBackoffCriteria()方法接收3个参数:第二个和第三个参数用于指定在多久之后重新执行任务,时间最短不能少于10秒钟;第一个参数则用于指定如果任务再次执行失败,下次重试的时间应该以什么样的形式延迟。这其实很好理解,假如任务一直执行失败,不断地重新执行似乎并没有什么意义,只会徒增设备的性能消耗。而随着失败次数的增多,下次重试的时间也应该进行适当的延迟,这才是更加合理的机制。第一个参数的可选值有两种,分别是LINEAR和EXPONENTIAL,前者代表下次重试时间以线性的方式延迟,后者代表下次重试时间以指数的方式延迟。
了解了Result.retry()的作用之后,你一定还想知道,doWork()方法中返回Result.success()和Result.failure()又有什么作用?这两个返回值其实就是用于通知任务运行结果的,我们可以使用如下代码对后台任务的运行结果进行监听:
1 | WorkManager.getInstance(this) |
这里调用了getWorkInfoByIdLiveData()方法并传入后台任务请求的id,会返回一个LiveData对象。然后我们就可以调用LiveData对象的observe()方法来观察数据变化了,以此监听后台任务的运行结果。
另外,你也可以调用getWorkInfosByTagLiveData()方法,监听同一标签名下所有后台任务请求的运行结果,用法是差不多的,这里就不再进行解释了。接下来,我们再来看一下WorkManager中比较有特色的一个功能——链式任务。
假设这里定义了3个独立的后台任务:同步数据、压缩数据和上传数据。现在我们想要实现先同步、再压缩、最后上传的功能,就可以借助链式任务来实现,代码示例如下:
1 | val sync = ... |
beginWith()方法用于开启一个链式任务,至于后面要接上什么样的后台任务,只需要使用then()方法来连接即可。另外WorkManager还要求,必须在前一个后台任务运行成功之后,下一个后台任务才会运行。也就是说,如果某个后台任务运行失败,或者被取消了,那么接下来的后台任务就都得不到运行了。